GoogleスプレッドシートでWEBサイトのURLから要素を抽出
更新日:2025年2月21日|公開日:2024年12月19日
色々なWEBサイトから情報をリアルタイムでスクレイピングをしたい場合などはGoogleスプレッドシートのIMPORTXML関数やIMPORTHTML関数が便利です。
今回はWEBサイト制作でCMSなどの規則性のあるコンテンツのタイトルや日付、URLなどを抽出したいケースを想定した手順をまとめたいと思います。
抽出したい範囲のURLのリストを作成
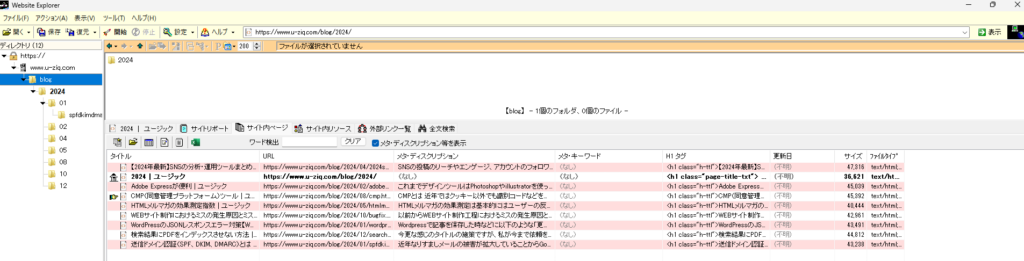
まずは抽出したい範囲のURLのリストを作成します。これを作成するために私はWebサイトエクスプローラーというWindowsのアプリを利用しています。割とこの界隈では有名なソフトなので使い方などは省略いたします。
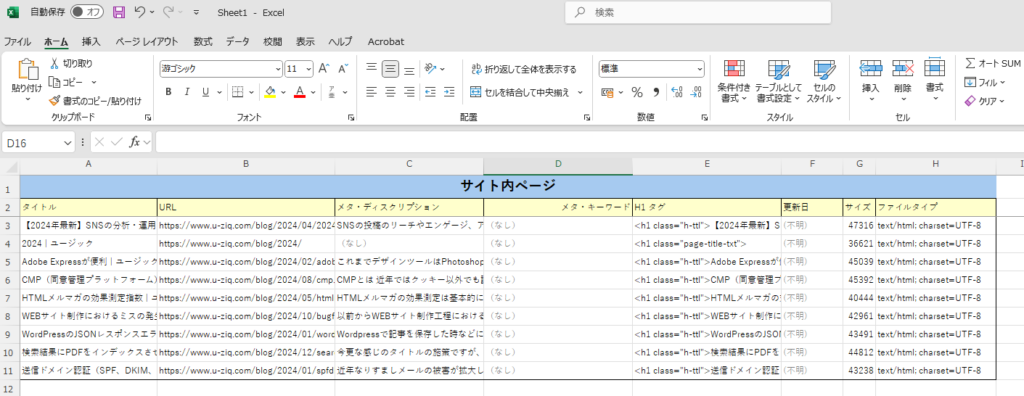
このアプリでは抽出したいURLとタイトルの抽出までを行いエクセルでエクスポートします。
Googleスプレッドシートでスクレイピング
先ほど作成したURLのリストをGoogleスプレッドシートにインポートします。
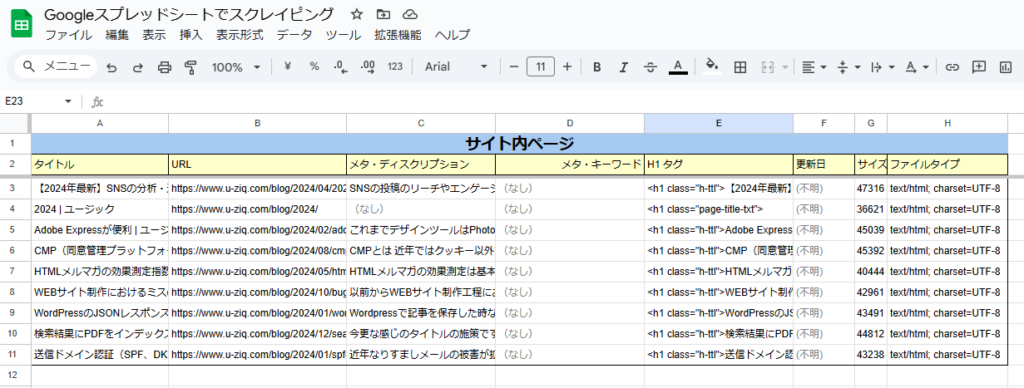
抽出したい要素の関数作る
使用する関数はIMPORTXML関数です。この関数を使ってまずはタイトルを抽出したいと思います。
要素を抽出する際は以下の関数を記載します。
=IMPORTXML("URL","XPathクエリ")XPathの取得はChromeのデベロッパーツールを使います。取得したい要素を選択してコピーからXPathをコピーを押すとXPathクエリがコピーできます。
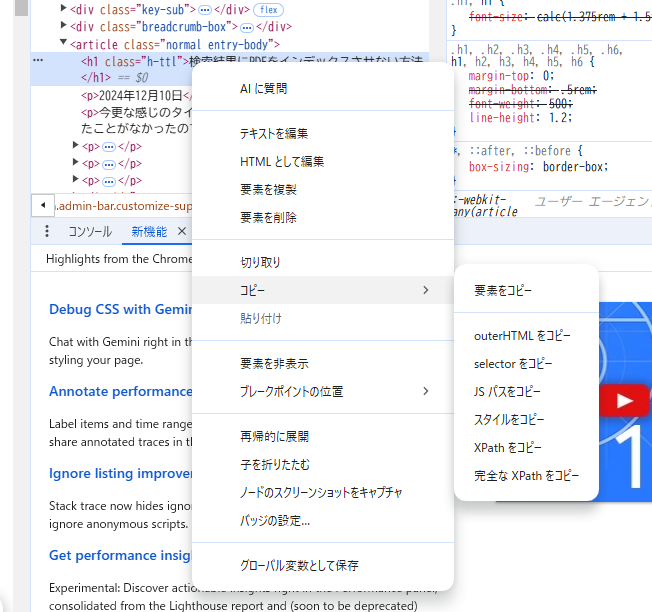
要素内にタグなどのダブルクォーテーションがある場合はシングルクォーテーションに変更してください。
以下の例だと
//*[@id="example"]/div/div[1]“example”のダブルクォーテーションとシングルクォーテーションに変更します。
//*[@id='example']/div/div[1]実際にこのブログの要素を取得する
このブログのタイトルなら以下になります。
/html/body/article/h1Googleスプレッドシートに記載します。※URLはセルを参照する形に変更しています。
=IMPORTXML(A3,"/html/body/article/h1")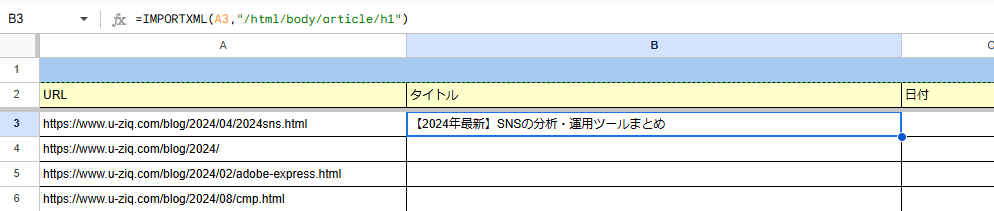
日付やその他の要素なども同じ要領で取得することができます。
ただCMSのウィジウィグで作った本文など特定のHTMLをタグごと抽出することはできません。その場合はGASを使ってスクレイピングになりそうです。※Parserライブラリが必要とのこと。
GAS(Google Apps Script)でよく使うコード集 – K.Y. Design
エクセルなら私がかなり昔に作ったマクロなどが便利かもしれません。正規表現で無理やりしてるので抽出できないことのほうが多いですが。
URLから特定箇所のHTMLを抽出して文字数をカウントするマクロ
ChatGPT4oとPythonの組み合わせ
ちなみに最近はこういう業務系のプログラム用途はChatGPT4oに聞きながらPythonとエクセルで作るのが速いし最強だなと思っていますが。※基本的なプログラム知識と的確な指示ができると結構なんでも作れたりします。
WEBサイトのUI/UXやSEO対策・AIO対策といったWEB関連が専門。
大阪のWEB制作会社でプランナー・ディレクターとして活動。
趣味はバンドでギター、ベース、ドラムなど。
キャンプや登山も好きでよく行ってます。